
AiPE
2. 크롬 개발자 도구 Network Request URL 파이썬으로 받아오기 본문
2. 크롬 개발자 도구 Network Request URL 파이썬으로 받아오기
Oshimaker XiBBaL 2023. 2. 1. 23:14직전 개발일지에서도 말했듯이 크롬 개발자도구(F12) > Network 탭 > 특정 Element 선택 > Request URL을 확인할 수 있으며 이를 요청하면 파일을 다운받을 수 있다.
https://xibbal-lab.tistory.com/32
1. Laftel Downloader 구상 및 관련 법령 조사
국내 애니 스트리밍 서비스 플랫폼인 라프텔에서 영상을 다운받을 수 있는 라프텔 영상 다운로더를 개발해보려고 한다. https://laftel.net/ https://laftel.net/ laftel.net 1. 개발 목표 제목 그대로 라프텔
xibbal-lab.tistory.com
이번엔 그 기능을 파이썬으로 구현해보겠다.
1. 라프텔 사이트 조사
아래는 특정 라프텔 URL에 들어가서 애니를 재생시킨 후의 Network탭의 모습이다.
.m4s형식으로 된 segment파일이 계속 받아지는 것을 확인할 수 있다.
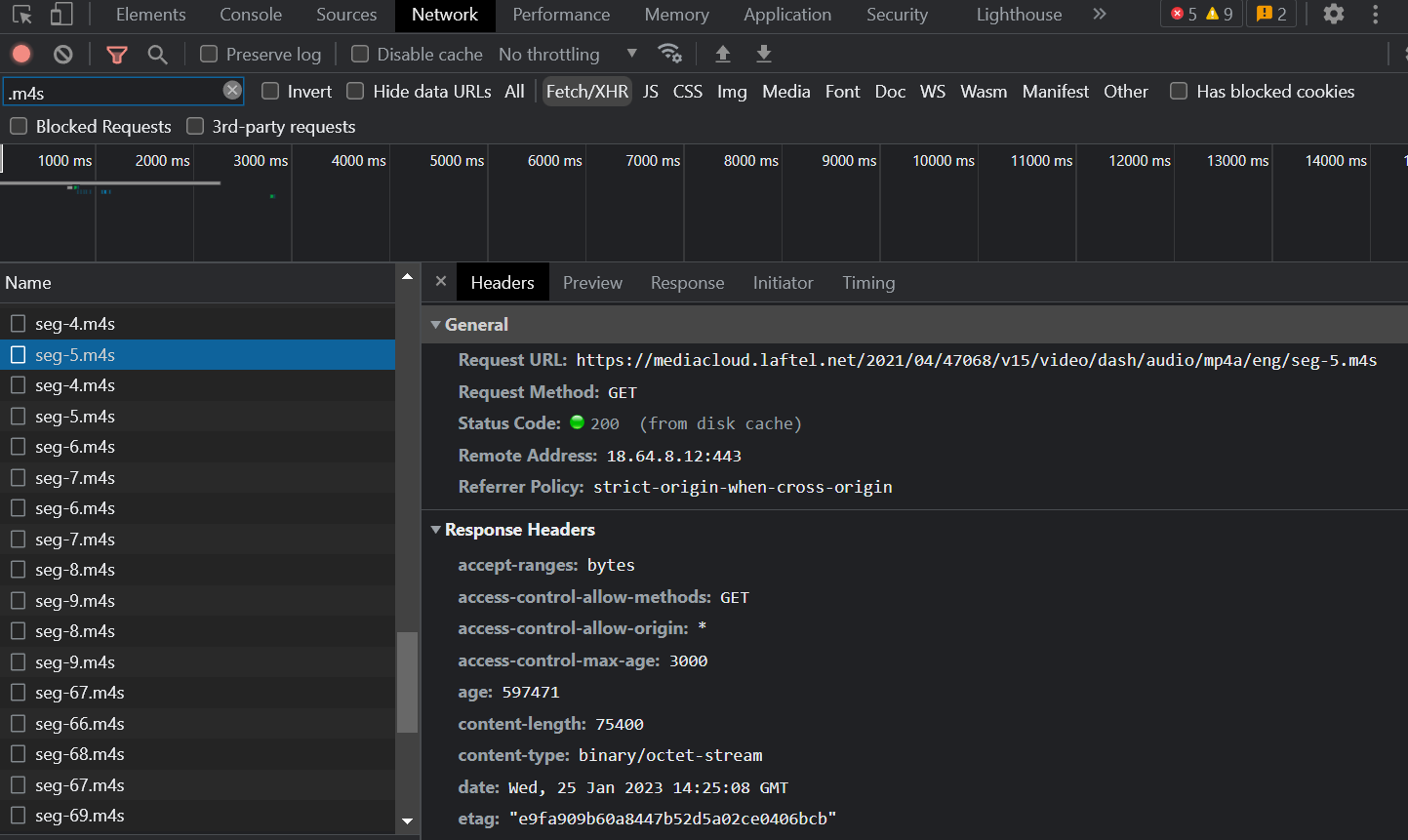
아래는 Request URL 주소의 예시이다.
seg-1.m4s (오디오 세그먼트)
https://mediacloud.laftel.net/2022/05/57855/v15/video/dash/audio/mp4a/und/seg-1.m4s
seg-1.m4s (비디오 세그먼트)
https://mediacloud.laftel.net/2022/05/57855/v15/video/dash/video/avc1/2/seg-1.m4s
seg-2.m4s (오디오 세그먼트)
https://mediacloud.laftel.net/2022/05/57855/v15/video/dash/audio/mp4a/und/seg-2.m4s
seg-2.m4s (비디오 세그먼트)
https://mediacloud.laftel.net/2022/05/57855/v15/video/dash/video/avc1/2/seg-2.m4s
1.
같은 파일명의 m4s가 2개씩 있는 이유는 Request URL을 보면 알 수 있다.
링크 중간에 /video/avc1/ 가 써있는 파일은 비디오 세그먼트 파일이고
링크 중간에 /audio/mp4a/ 가 써있는 파일은 오디오 세그먼트 파일이다.
avc1은 H.264 규격의 코덱에서 등장하는 용어이고 mp4a는 오디오 파일 관련 용어다. 궁금하면 구글에 쳐보자.
2.
한 영상의 세그먼트들은 seg-숫자.m4s 부분 빼고는 Request URL이 모두 같다. 당연한 말이긴 하지만 가끔 이 Request URL을 랜덤하게 보내는 척 하는 사이트도 있다. 골치 아플 뻔한 부분인데 라프텔에서는 Request URL이 규칙성을 띠어 편했다. 세그먼트의 개수만 알면 다운받는건 쉽다.
3.
위 영상의 경우 23분 52초의 플레이타임을 가지고 있다. 따라서 세그먼트의 개수는 239개이다. 세그먼트 개수를 정하는 변수가 "영상의 길이"라는 점은 확실하지만 정확히 어떤 규칙으로 개수를 결정하는지는 더 알아봐야 할 부분.
아무튼 위의 영상의 경우 239개이므로 일단 이를 표준으로 진행한 후 나중에 수정하겠다.
2. Curl 명령어로 m4s 다운
Curl명령어는 특정 URL의 내용물을 요청해 다운받을 때 쓴다.
"curl + 특정url" 을 cmd에서 실행해주면 된다.
파이썬에서 cmd명령어를 사용할때는
import os
os.system("cmd명령어")
과 같은 형태로 쓰면 된다.
나는 239개의 비디오 세그먼트와 239개의 오디오 세그먼트에 대해 모두 각각 curl을 해줘야 하기 때문에 for in range(1,240)을 이용하겠다.
location = os.getcwd()
for i in range(1,240): #number of the .m4s segment file is constant at 239
vid_url = f"https://mediacloud.laftel.net/{found}/video/avc1/2/seg-{i}.m4s"
aud_url = f"https://mediacloud.laftel.net/{found}/audio/mp4a/eng/seg-{i}.m4s"
if i < 10: #for single digit num
os.system(f"curl {vid_url} > {location}/vids/vid00{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud00{i}.m4s")
sleep(random.randint(1,3))
elif i < 100: #for double digit num
os.system(f"curl {vid_url} > {location}/vids/vid0{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud0{i}.m4s")
sleep(random.randint(1,3))
else: #for three digit num
os.system(f"curl {vid_url} > {location}/vids/vid{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud{i}.m4s")
sleep(random.randint(1,3))코드설명
1.
f-string내의 "found"라는 변수는 Request URL의 일정한 중간 부분이다. 파이썬으로 크롬 개발자도구의 텍스트를 읽어와 위의 코드 앞에서 따로 지정해주어야한다.
2.
location변수는 현재 디렉터리의 위치를 반환한다. 저장 경로를 파이썬 파일 바로 옆으로 하고 싶어서 지정해주었다.
만약 curl을 할 때 디렉터리의 지정이 없으면 자동으로 최상위 디렉터리에 저장된다.
3.
sleep이 들어간 이유는 우리가 키보드 화살표 →키로 영상을 넘기면서 볼 때 세그먼트가 다운되는 속도와 비슷한 속도로 요청을 전송하기 위해서이다. sleep이 없으면 너무 빨리 다운이 되고 기계로 간주되어 IP차단을 당할까봐 미리 넣어뒀다.
(경험담이다.)
디버그1. cmd 정렬 순서 문제
원래는 if ~ else 구문이 없었는데, 저장된 세그먼트 숫자들의 자릿수를 맞추어주려고 일부러 넣었다. 원래대로 다운하면 나중에 cmd에서 ffmpeg로 파일을 모두 합칠때 순서가 내 의도와 다르게 나오더라. cmd는 윈도우 탐색기와 정렬하는 방법이 달라서 그렇다고 한다.
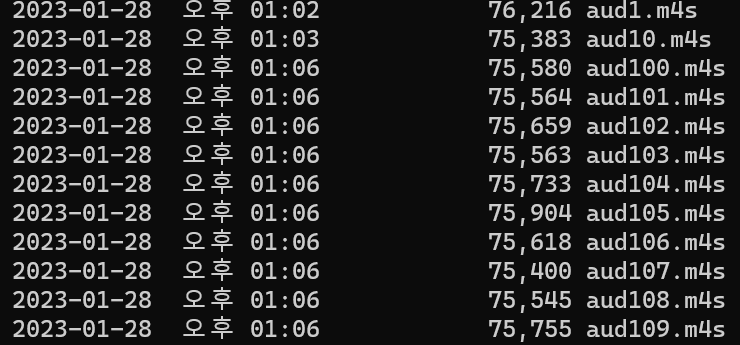
예를 들어 seg-1.m4s부터 seg-239.m4s까지 파일이 한 디렉터리에 존재한다고 해보자.
| 윈도우 탐색기의 정렬 → 1 2 3 4 5 6 7 8 9 10 11 12 .. 19 20 21 22 .. 99 100 101 ... 238 239 cmd의 정렬 → 1 10 100 101 102 .. |
윈도우 탐색기는 실제 정수의 순서대로 파일 이름을 정렬하지만 cmd는 그러하지 않다.
나중에 ffmpeg를 통해 영상을 합치고 인코딩할때 어차피 cmd명령어를 사용해야 하므로 이 차이는 미리 조정해둘 필요가 있어 보인다. 따라서 seg- 뒤의 숫자 자릿수를 맞춰 주는 방식을 택했다.
1자리수는 2개 2자리수는 1개 3자리수는 0개의 0이 들어가도록 코드를 짰다.
아래는 수정 전 후의 비교 스크린샷.

3. Curl 명령어로 init.mp4 다운
init.mp4파일은 하나밖에 없으므로 for loop 밖에 한번만 코드를 쓰면 된다.
init.mp4파일의 중간 부분도 segment파일의 중간 부분과 동일해서 앞에서 지정한 found변수를 그대로 적용해 쓸 수 있다.
location = os.getcwd()
os.system(f"curl https://mediacloud.laftel.net/{found}/video/avc1/2/init.mp4 > {location}/vids/vid_init.mp4")
os.system(f"curl https://mediacloud.laftel.net/{found}/audio/mp4a/eng/init.mp4 > {location}/auds/aud_init.mp4")
os.system(f"curl https://mediacloud.laftel.net/{found}/stream.mpd > {location}/stream.mpd")
4. Request URL 크롬 개발자도구에서 Python으로 읽어오기
사실 여기가 이번 일지의 메인이다. 이거 되게 하느라 좀 힘들었다.
코드부터 까놓고 설명해보겠다.
def get_request_url():
caps = DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'performance': 'ALL'}
driver = webdriver.Chrome(desired_capabilities=caps)
driver.get(laftel_url)
time.sleep(10) #wait for the loading
perf = driver.get_log('performance')
serialized_perf = json.dumps(perf) #serialize perf(type==dict) for json.dumps() method
# for Data Research, code below will save .txt log named "perflog.txt" (same context with Chrome Developer tools - Network Tab)
# f = open("perflog.txt", 'w', encoding='utf-8')
# f.write(serialized_perf)
# f.close()
m = re.search('https://mediacloud.laftel.net/(.+?)/stream.mpd', serialized_perf)
if m:
global found
found = m.group(1)
코드설명
1.
아까 앞에서 언급했던 found변수에 Requet URL의 공통부분(중간부분)을 할당하는게 이 코드의 목표이다.
2.
나중에 함수를 호출해 쉽게 쓰기 위해서 get_request_url()이라는 함수 아래에 작성했다.
3.
perf = driver.get_log('performance')
위 문장이 중요한데, Chrome의 개발자 도구에 직접 접근할 방법이 없어서 고민하던 중 한 가지 방법을 알아냈는데 그 방법을 구현한 코드이다. 저런게 있는지 알아내는데 힘들었다.
개발자도구의 Network탭에 표시되는 여러가지 엘리멘트들이 모두 포함된 로그 파일이 존재하는데, 위 코드로 처리하면 'performance' 라는 변수에 저장된다. 이 변수를 print해보면 엄청 더러운 규칙으로 엘리멘트 이름과 각각의 request url이 적혀 있다.
위 performance 변수의 내용을 아래 코드로 perflog.txt 안에 저장해서 분석해보자.
# for Data Research, code below will save .txt log named "perflog.txt" (same context with Chrome Developer tools - Network Tab)
f = open("perflog.txt", 'w', encoding='utf-8')
f.write(serialized_perf)
f.close()
나중에 실제로 동작시킬때는 #으로 주석처리해놓을 예정이다.
performance변수 안에 저장된 내용을 살짝만 올려보자면 아래와 같다.
| perflog.txt 내용 일부 |
| [{"level": "INFO", "message": "{\"message\":{\"method\":\"Network.requestWillBeSent\",\"params\":{\"documentURL\":\"https://laftel.net/player/40269/46123\",\"frameId\":\"C42151F49BB89B40CF0C200E4D1C947D\",\"hasUserGesture\":false,\"initiator\":{\"type\":\"other\"},\"loaderId\":\"E3EDF1300CB6B9872D1610E457262DB0\",\"redirectHasExtraInfo\":false,\"request\":{\"headers\":{\"Upgrade-Insecure-Requests\":\"1\",\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36\",\"sec-ch-ua\":\"\\\"Not_A Brand\\\";v=\\\"99\\\", \\\"Google Chrome\\\";v=\\\"109\\\", \\\"Chromium\\\";v=\\\"109\\\"\",\"sec-ch-ua-mobile\":\"?0\",\"sec-ch-ua-platform\":\"\\\"Windows\\\"\"},\"initialPriority\":\"VeryHigh\",\"isSameSite\":true,\"method\":\"GET\",\"mixedContentType\":\"none\",\"referrerPolicy\":\"strict-origin-when-cross-origin\",\"url\":\"https://laftel.net/player/40269/46123\"},\"requestId\":\"E3EDF1300CB6B9872D1610E457262DB0\",\"timestamp\":122888.673653,\"type\":\"Document\",\"wallTime\":1674870554.971668}},\"webview\": (중략) \"none\",\"referrerPolicy\":\"strict-origin-when-cross-origin\",\"url\":\"https://mediacloud.laftel.net/2021/04/46773/v15/video/dash/video/avc1/2/seg-1.m4s\"},\"requestId\":\"1752.120\",\"timestamp\":122892.669232,\"type\":\"Fetch\",\"wallTime\":1674870558.966296}},\"webview\": (후략) |
이딴식으로 알아먹기 힘들게 써있다.
내가 해야 할 것은 .m4s라는 문자열을 찾아서 그 URL의 중간 부분을 found 변수에 복사해오는 것이다.
.m4s파일이 굉장히 많기 때문에 .m4s로 끝나는 단어가 굉장히 많은데, 위 코드대로 하면 performance 변수 내용의 맨 앞부터 검사하기 때문에 맨 앞에 있는 .m4s파일의 Request URL을 가져오게 된다.
위 perflog.txt 파일 내용 중 밑줄+진하게 해 놓은 부분이 내가 필요한 부분이다.
디버그1. 문자열이 잘못 잘리는 문제
특정 문자열 사이를 추출해내는 방법에 대해서는 아래 포스팅을 참고.
https://xibbal-lab.tistory.com/30
모든 애니의 Request URL에 고정적인 문자인
"https://mediacloud.laftel.net" 과 "seg-1.m4s" 사이를 위 방법을 통해 잘라내려고 했더니만 내가 원하는 부분 앞에 "https://mediacloud.laftel.net"로 시작하는 다른 Request URL이 존재해서 버그가 생겼다.
앞에 등장한 "https://mediacloud.laftel.net" 부분에서부터 내가 원하는 부분을 포함한 .m4s 문자까지가 잘라져 출력된 것으로 보인다.
앞에 등장한 "https://mediacloud.laftel.net"으로 시작하는 Request URL이 뭔지 확인해봤더니 stream.mpd 파일이었다.
| ... "none\",\"referrerPolicy\":\"strict-origin-when-cross-origin\",\"url\":\"https://mediacloud.laftel.net/2021/04/46773/v15/video/dash/stream.mpd\"},\"requestId\":\"1752.101\",\"timestamp\":122891.702101,\"type\":\"Fetch\",\"wallTime\":1674870558.000573}},\"webview\": ... |
stream.mpd파일의 중간부분도 .m4s파일의 중간부와 같길래 그냥 stream.mpd 파일을 기준으로 하기로 했다.
5. 최종 코드
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
from time import sleep
import json
import re
import os
import random
laftel_url = input("Type laftel link\n")
# below is the test url
# laftel_url = "https://laftel.net/player/40269/46123"
def get_request_url():
caps = DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'performance': 'ALL'}
driver = webdriver.Chrome(desired_capabilities=caps)
driver.get(laftel_url)
time.sleep(10) #wait for the loading
perf = driver.get_log('performance')
serialized_perf = json.dumps(perf) #serialize perf(type==dict) for json.dumps() method
# for Data Research, code below will save .txt log named "perflog.txt" (same context with Chrome Developer tools - Network Tab)
# f = open("perflog.txt", 'w', encoding='utf-8')
# f.write(serialized_perf)
# f.close()
m = re.search('https://mediacloud.laftel.net/(.+?)/stream.mpd', serialized_perf)
if m:
global found
found = m.group(1)
def curl_m4s():
for i in range(1,240): #number of the .m4s segment file is constant at 239
vid_url = f"https://mediacloud.laftel.net/{found}/video/avc1/2/seg-{i}.m4s"
aud_url = f"https://mediacloud.laftel.net/{found}/audio/mp4a/eng/seg-{i}.m4s"
if i < 10: #for single digit num
os.system(f"curl {vid_url} > {location}/vids/vid00{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud00{i}.m4s")
sleep(random.randint(1,3))
elif i < 100: #for double digit num
os.system(f"curl {vid_url} > {location}/vids/vid0{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud0{i}.m4s")
sleep(random.randint(1,3))
else: #for three digit num
os.system(f"curl {vid_url} > {location}/vids/vid{i}.m4s")
os.system(f"curl {aud_url} > {location}/auds/aud{i}.m4s")
sleep(random.randint(1,3))
get_request_url()
request_url_vid = f"https://mediacloud.laftel.net/{found}/video/avc1/2/seg-num.m4s"
request_url_aud = f"https://mediacloud.laftel.net/{found}/audio/mp4a/eng/seg-num.m4s"
# In the case of audio-related m4s files, there are cases where the request_url of the old anime is /und/ instead of /eng/. but in test link abovem, /eng/ is correct.
# I will make another version which is able to download /und/ link anime later.
location = os.getcwd()
os.system(f"curl https://mediacloud.laftel.net/{found}/video/avc1/2/init.mp4 > {location}/vids/vid_init.mp4")
os.system(f"curl https://mediacloud.laftel.net/{found}/audio/mp4a/eng/init.mp4 > {location}/auds/aud_init.mp4")
os.system(f"curl https://mediacloud.laftel.net/{found}/stream.mpd > {location}/stream.mpd")
curl_m4s()
위 코드를 실행하면 라프텔 서버측에서 init.mp4와 모든 segment.m4s를 받아와서 비디오 init과 segment는 vids/ 폴더에, 오디오 init과 segment는 auds/ 폴더에 저장한다.
Selenium 4.0버전에서는 크롬 개발자도구에 performance 로그를 경유하지 않고도 직접 접근하는 기능을 추가한다고 한다. 이미 파이썬 이외의 Java 등의 언어에서는 구현중인 기능인 듯 하는데 기대가 된다.
'[XiBBaL] Development Project > Laftel Downloader' 카테고리의 다른 글
| 4. Shaka Packager 분석 및 복호화(Decrypt) 방법 고안 (9) | 2023.02.04 |
|---|---|
| 3.5. 스택 오버플로우 질문 : Not able to merge init.mp4 and seg-*.m4s with ffmpeg and python due to its file format difference 번역 (0) | 2023.02.04 |
| 3. m4s파일과 init.mp4 ffmpeg로 병합하기 (3) | 2023.02.01 |
| 1. Laftel Downloader 구상 및 관련 법령 조사 (2) | 2023.02.01 |

